Machine heart report
Editor: Chen Ping, Devil
The training of deep learning model is like "black box operation", knowing what the input is and what the output is, but the intermediate process is like a black box, which makes researchers spend a lot of time to find out why the model is not working properly. It would be great if there is a visual tool that can help researchers better understand the model behavior.
Recently, Google researchers released a language interpretability tool (LIT), which is an open source platform for visualizing and understanding natural language processing models.
Address: https://arxiv.org/pdf/2008.05122.pdf.
Project address: https://github.com/PAIR-code/lit.
LIT focuses on the core issues of model behavior, including: Why does the model make such predictions? When is the performance poor? What happens when the input changes are controllable? LIT integrates local interpretation, aggregation analysis and counterfactual generation into a streamlined browser-based interface to realize rapid exploration and error analysis.
This study supports a variety of natural language processing tasks, including exploring the counterfactual of emotional analysis, measuring gender bias in the coreference system, and exploring local behaviors in text generation.
In addition, LIT also supports a variety of models, including classification, seq2seq and structured prediction models. And it is highly extensible and can be extended through declarative and framework-independent API.
For related demo, see the video:
It can be reconfigured for novel workflow, and these components are independent, portable and easy to implement.
User Interface(UI)
LIT is located in a single-page web application, which consists of multiple toolbars and a main part with multiple independent modules. If modules are applicable to the current model and data set, they will be displayed automatically. For example, the module that displays the classification results is only displayed when the model returns MulticlassPreds.
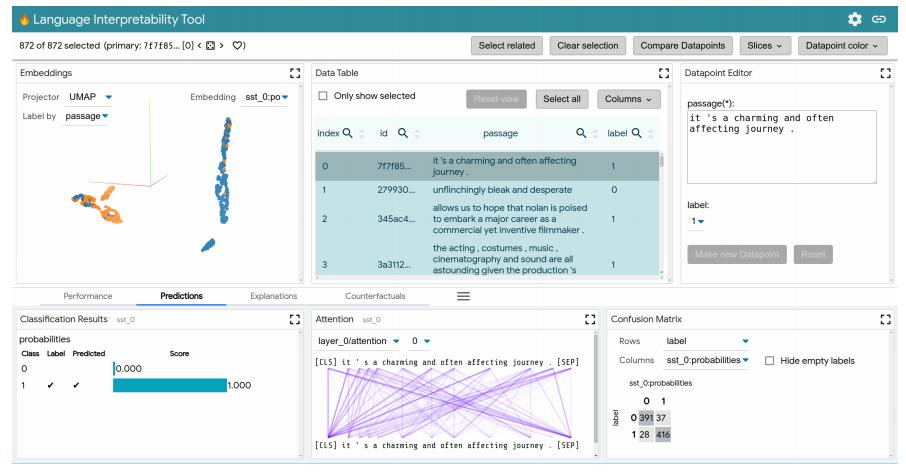
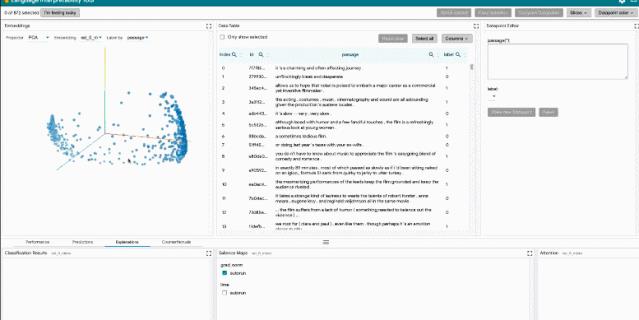
LIT user interface
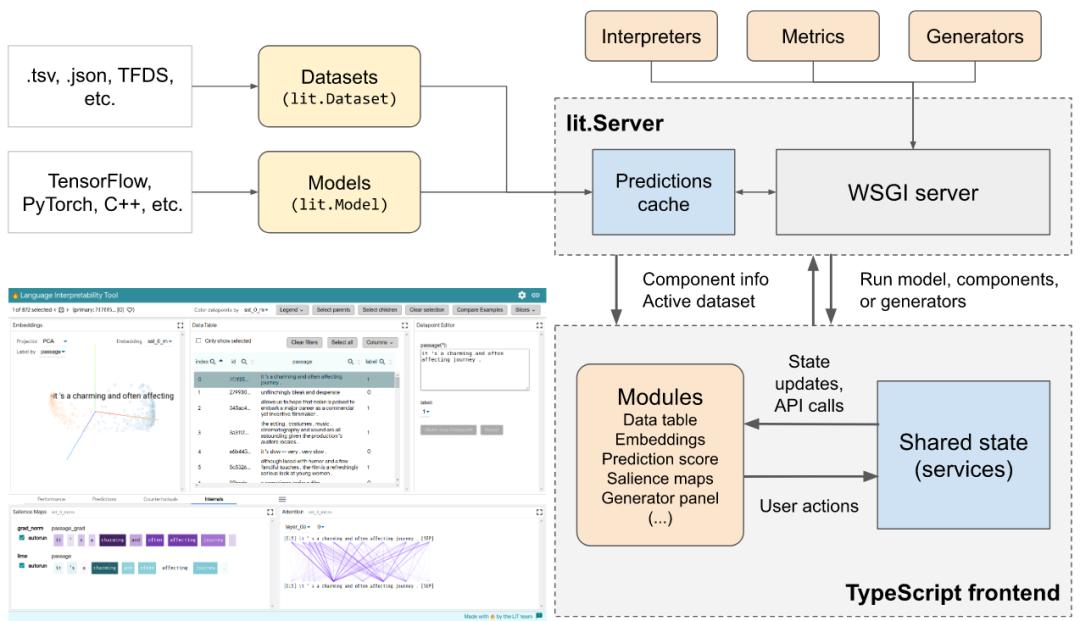
The layout design of LIT.
function
LIT supports various debugging workflows through a browser-based user interface (UI). Functions include:
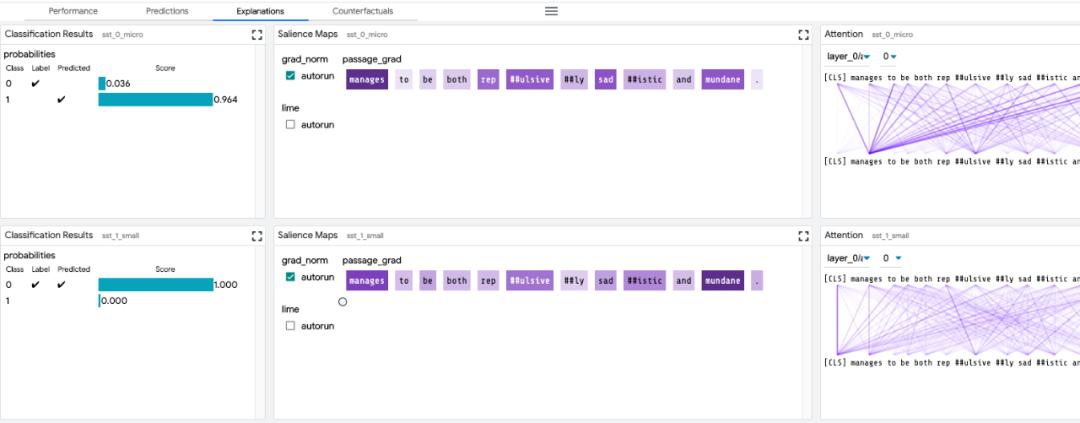
Local interpretation: it is carried out through the saliency map, attention map and rich visualization map predicted by the model.
Aggregation analysis: including user-defined metrics, slicing and binning, and visualization of embedded space.
Counterfactual generation: create and evaluate new examples dynamically by manually editing or generating plug-ins for counterfactual reasoning.
Side-by-side mode: Compare two or more models, or one model based on a pair of examples.
Highly extensible: it can be extended to new model types, including classification, regression, span labeling, seq2seq and language modeling.
Frame-independent: compatible with TensorFlow, PyTorch, etc.
Let’s look at several main modules of LIT:
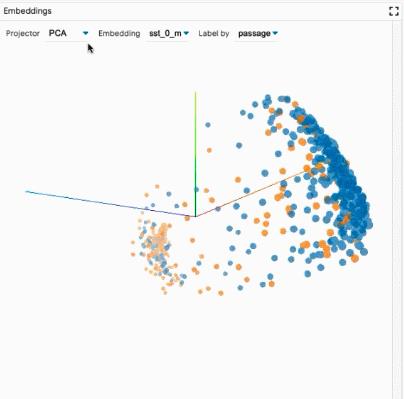
Exploring data sets: Users can interactively explore data sets using different standards across modules (such as data tables and embedded modules), thus rotating, scaling and translating PCA or UMAP projections to explore clusters and global structures.
Compare models: By loading multiple models in the global settings control, LIT can compare them. Then copy the submodule that displays the information of each model to facilitate the comparison between the two models. Other modules (such as embedded module and measurement module) are updated at the same time to display the latest information of all models.
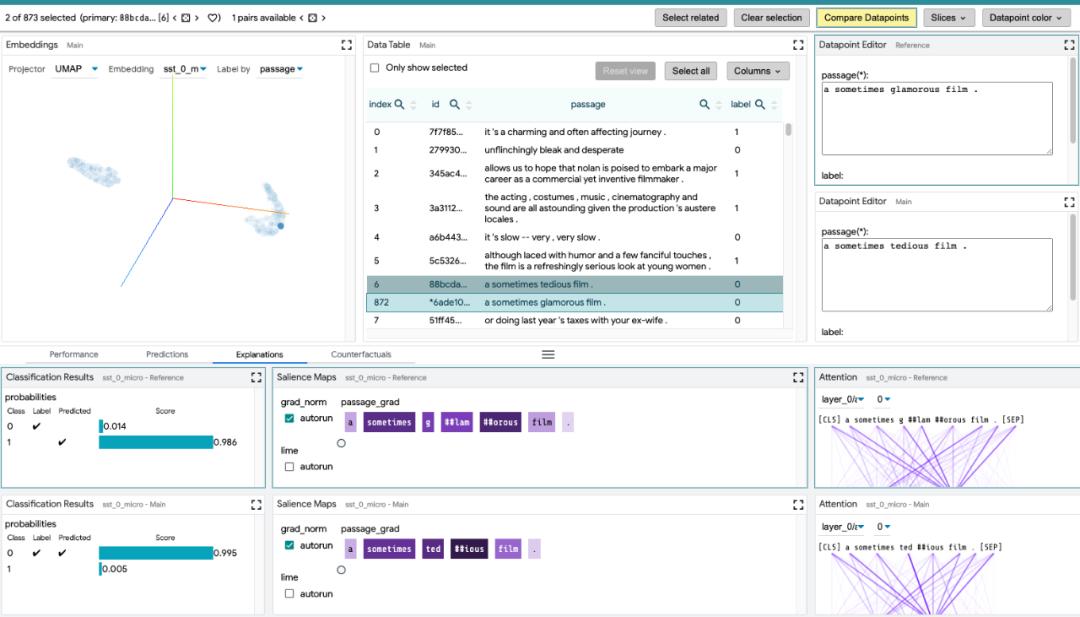
Compare datapoints: switch to the "Compare data points" button in the selection toolbar to make LIT enter the data point comparison mode. In this mode, the main data point is selected as the reference data point, and it will be used as the reference point for comparison in subsequent settings. Reference data points are highlighted in the data table with a blue border.
See: https://github.com/pair-code/lit/blob/main/docs/user _ guide.md for details of other modules.
After reading the above introduction, are you eager to get started and try this cool visualization tool? Let’s take a look at its installation process and examples.
Installation tutorial
Download the software package and configure Python environment. The code is as follows:
git clone https://github.com/PAIR-code/lit.git ~/lit# Set up Python environmentcd ~/ litconda env create -f environment.ymlconda activate lit-nlpconda install cudnn cupti # optional, for GPU supportconda install -c pytorch pytorch # optional, for PyTorch# Build the frontendcd ~/lit/lit_nlp/clientyarn && yarn build
After installing and configuring the environment, you can experience the examples included in the toolkit.
example
1. Example of emotional classification
The code is as follows:
cd ~/litpython -m lit_nlp.examples.quickstart_sst_demo –port=5432
The example of emotion classification is a fine-tuned BERT-tiny model based on Stanford Emotion Tree Library, which can be completed in less than 5 minutes on GPU. After the training is completed, it will start the LIT server on the development set.
2. Language modeling class example
To explore the prediction results of the pre-training model (BERT or GPT-2), run the following code:
cd ~/litpython -m lit_nlp.examples.pretrained_lm_demo –models=bert-base-uncased –port=5432
For more examples, please refer to the directory: /lit_nlp/examples.
In addition, the project also provides a way to add your own models and data. By creating a customized demo.py launcher, users can easily run LIT with their own models, similar to the above sample directory /lit_nlp/examples.
See: https://github.com/pair-code/lit/blob/main/docs/python _ api.md # adding-models-and-data for the complete adding process.
Reference link:
http://www.iibrand.com/news/202008/1719096.html
https://github.com/PAIR-code/lit/blob/main/docs/user_guide.md
https://github.com/PAIR-code/lit/blob/main/docs/python_api.md#adding-models-and-data
https://medium.com/syncedreview/google-introduces-nlp-model-understanding-tool-ab840b456be3
Amazon SageMaker is a fully hosted service that can help developers and data scientists quickly build, train and deploy machine learning models. SageMaker completely eliminates the heavy work of each step in the machine learning process, making it easier to develop high-quality models.
Now, enterprise developers can get 1000 yuan service vouchers for free, easily get started with Amazon SageMaker, and quickly experience five examples of artificial intelligence applications.
? THE END
Please contact Ben WeChat official account for authorization.
Contribute or seek reports: content@jiqizhixin.com.
Original title: "LIT, Google Open Source NLP Model Visualizer, Model Training is no longer a" black box ""
Read the original text
关于作者